数据库
字数
5049 字
阅读时间
21 分钟
一、简介
- 数据库:长期存储在计算机内的、有组织的。简而言之,数据库就是一个存储数据的仓库
- 应用场景:
- 页面复杂数据正确性校验(功能测试,测页面功能)。如:统计每日新增用户多少
- 测试数据的构造(性能测试)。如:商城系统需要构造一些商品/用户信息
- 数据的清洗。如:系统上线前基础数据的去重,垃圾数据的清理等
- 数据库分类:
- 🌟关系型数据库:以形式存储数据
- 非关系型数据库:非表格存储数据【了解】
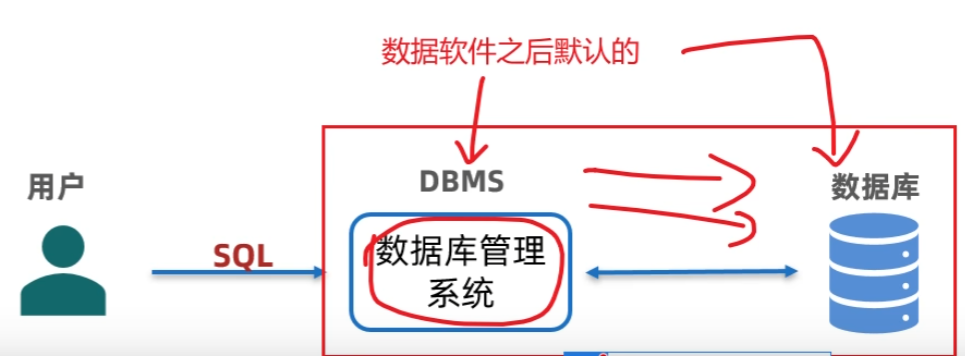
- 常见数据库管理系统(DBMS)
- 关系型(RDBMS):MySQL、Oracle
- SQL语言只能用于操作关系型数据库,且关系型数据库的SQL语言基本都类似
- 非关系型:Redis、HBase
- 数据库管理系统是下载MySQL、Oracle、Redis等数据库后默认自带有的,默认其中有数据库,也可以通过DBMS创建修改数据库
- 关系型(RDBMS):MySQL、Oracle
1.SQL
- Structured Query Language(结构化查询语言),通过SQL语言可以对关系型数据库进行操作
- 特点:
- 通用性:常见都可以通过SQL语言操作
- 简洁性:语言简洁,易学易用
- SQL语句关键词:
- 数据操作:insert(增)、delete(删)、update(改)、select(查)
- 数据定义(对数据表和数据库):create(创建)、alter(修改)、drop(删除)
2.MySQL数据库
- MySQL:企业级关系型数据库管理系统,目前是隶属于Oracle公司的产品
- 构成:
- 客户端:下发用户要执行的SQL语句,并显示服务器返回的执行结果。【命令行/第三方可视化界面】
- 如:命令行客户端使用
mysql(.exe) -u root -p执行登录操作
- 如:命令行客户端使用
- 服务端:存储数据并解析编译后的SQL语句,将执行结果返回给客户端
- 客户端:下发用户要执行的SQL语句,并显示服务器返回的执行结果。【命令行/第三方可视化界面】
- MySQL数据库连接
- 工具客户端:DataGrip、DBeaver、Navicat
- 服务端:Vmware虚拟机(已安装mysqld服务)
二、数据库操作(针对整个数据库的操作) --> SQL语句
字符集:有相同属性的字符的组合。例如:支持中文符号的字符集utf8。utfmb4是utf8的扩展版
排序规则:将字符集转化为计算机识别的进制的规则。例如:支持中文字符集utf8的一般规则utf8_general_ci- SQL语句规则:
- SQL不区分大小写
- SQL语句结束标志 --> 英文格式分号
- 变量名构成:字母、数字、下划线
- 数据库常见操作:
- 创建数据库:
create database 数据库名 charset 字符集 collate 排序规则;
- 使用数据库:
use 指定数据库名 - 查看正在使用的数据库:
select database();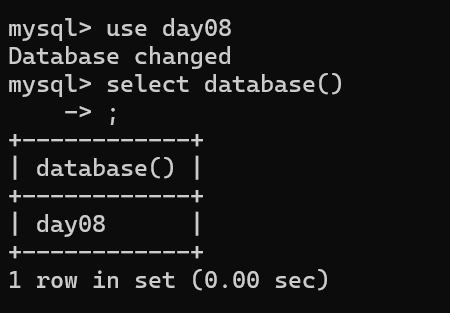
- 修改数据库:
alter database 库名 charset 字符集 collate 排序规则; - 删除数据库:
drop database 库名;--> 数据库和数据表的删除都使用 drop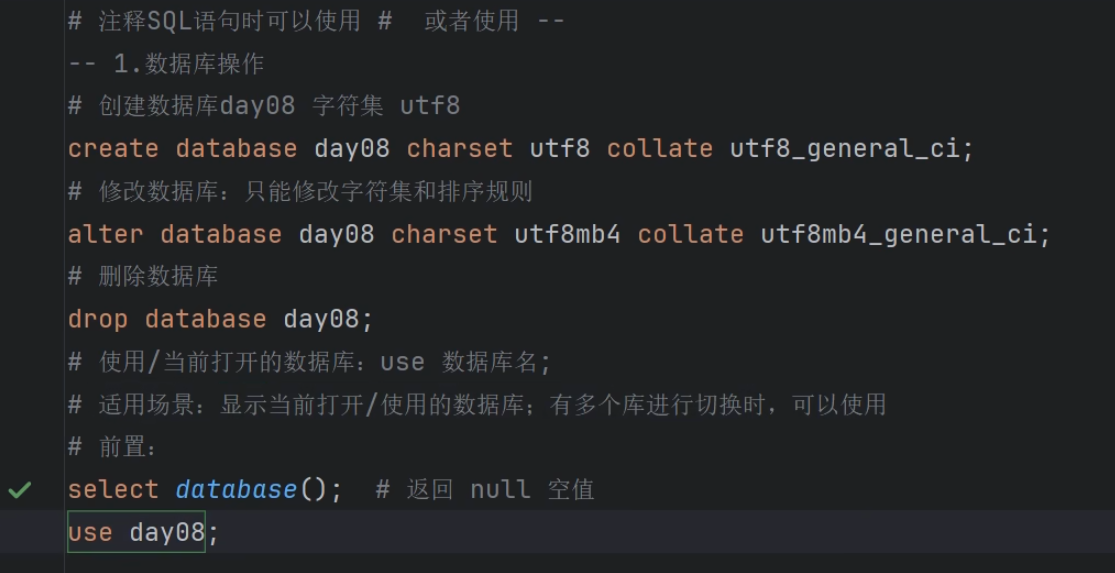
- 创建数据库:
三、数据库引擎
MySQL 支持插件式存储引擎,不同引擎对应不同存储、索引、事务、并发策略,面试常问5 种核心引擎,重点是 InnoDB。
0. 核心分类及特点
- MySQL的核心特点是插件式存储引擎架构;数据库服务器与存储引擎分离,你可以为不同的表设置不同的存储引擎(一张表只能用一种),MySQL5.5及以后的默认存储引擎是InnoDB(也是目前最主流的)
- 简单的说:存储引擎决定了数据表【怎么存数据、怎么处理并发、支不支持回滚、崩了能不能恢复】
- MySQL最核心、最实用的分类维度是是否支持事务,这直接决定了引擎的适用场景,分为两大类:
- 事务型存储引擎:支持 ACID 事务特性(原子性、一致性、隔离性、持久性),支持崩溃恢复、行级锁,适合有数据一致性要求的业务(如电商、金融)。
- 非事务型存储引擎:不支持事务,通常是表级锁,读写速度快,但崩溃后可能丢数据,适合只读/少写、对一致性要求低的静态数据业务。
1.主流存储引擎(必背)
仅InnoDB为事务型数据库,可使用
show engines;命令查看MySQL支持的所有存储引擎
1)InnoDB(MySQL 5.5+ 默认引擎)
- 支持事务:ACID 完整事务、回滚、崩溃恢复
- 行级锁:并发高、适合大量读写
- 外键约束:唯一支持外键的引擎
- 索引:聚簇索引(主键高效),支持 B+ 树
- 适用场景:电商、金融、订单、支付、高并发业务
2)MyISAM(5.5 前默认)
- 不支持事务、不支持外键
- 表级锁:并发差,写入会阻塞全表
- 查询极快:count (*) 直接读取元数据
- 适用场景:只读 / 少写、日志系统、静态数据展示
3)Memory(Heap)
- 数据存内存:速度极快
- 重启丢失数据、不支持事务
- 表级锁、支持哈希索引
- 适用场景:临时表、缓存、会话数据
4) CSV
- 以 CSV 格式存储,可直接用 Excel 打开
- 不支持索引、不支持大字段
- 适用:数据交换、简单导入导出
5)Archive
- 只支持 INSERT/SELECT,不支持删除 / 修改
- 高压缩、占用空间极小
- 适用:日志、审计、历史归档
2.核心对比(面试高频)
表格
| 引擎 | 事务 | 锁粒度 | 索引 | 适用场景 |
|---|---|---|---|---|
| InnoDB | 支持 | 行锁 | 聚簇索引 | 高并发、业务系统 |
| MyISAM | 不支持 | 表锁 | 非聚簇 | 读多写少 |
| Memory | 不支持 | 表锁 | 哈希 | 临时缓存 |
3.面试一句话总结
- 90% 业务用 InnoDB:要事务、并发、安全就选它
- MyISAM:老项目、纯查询用
- Memory:临时数据、速度优先
四、数据表操作
- 查表结构操作:
desc 表名 - 删除表:
drop table 表名
五、常用SQL语法
- 去重查询:
select distinct 字段名 from 表名--> distinct 关键字去重 - 限定返回行数:
select 字段名 from 表名 limit 行数--> 返回 指定行数的数据 - 查询字段后将该字段改名:SQL
select 字段1 as 别名1, 字段2 as 别名2 from 表名; - 新增数据:
insert into 表名 values(值1, 值2, ...), (值1, 值2, ...);--> 插入多条记录- 也可指定插入某几列的数据:
insert into 表名 (列1, 列2, ...) values(值1, 值2, ...);
- 也可指定插入某几列的数据:
- 修改数据:
update 表名 set 字段=值 where 条件;--> 常见条件:字段 = 值 - 删除表中的数据:
delete from 表名 where 条件; - 查询数据:
select * from 表名;--> * 表示任意字段 - 保留x位小数:
round(number, digits)--> number:要四舍五入的浮点数;digits(默认0):为正数x,则保留x位小数,为0,则四舍五入为整数;为负数y,则在小数点左侧y位进行四舍五入
数据复杂查询
别名
- 复杂的名称可以起别名以便于编写语句
- 数据表起别名:表名 as 别名
- 字段起别名:字段名 as 别名
- 起别名的关键字 as 可以省略,例如:表名 别名
- 数据表起别名后,查询必须要使用表别名;字段别名看情况使用(不能用在 WHERE 和标准 GROUP BY 中)
练习用数据表:students、courses、scores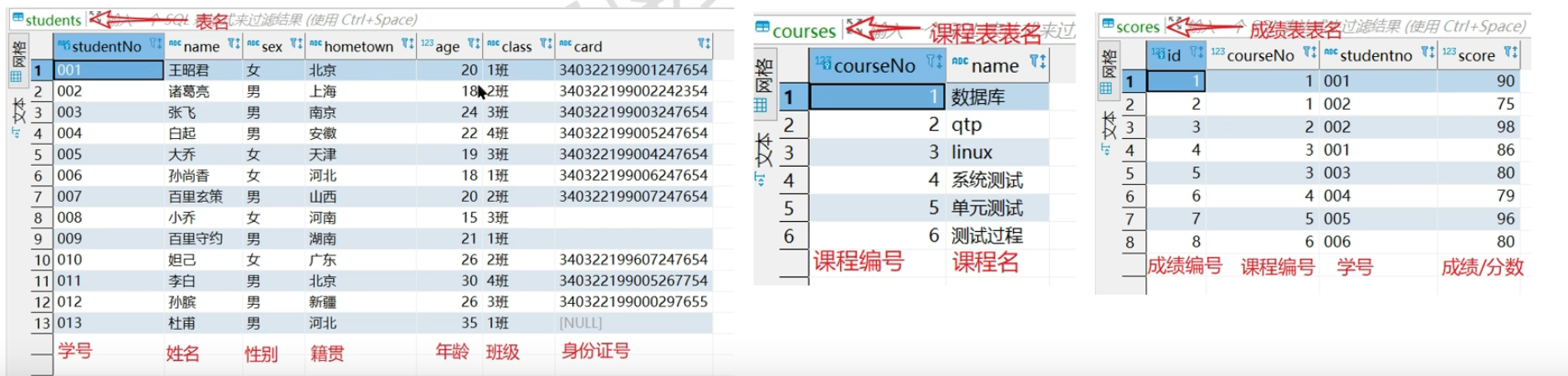
1)🌟条件查询(重要,不难)
空字符串 --> 字符 = ""基础语法:
select * from 表名 where 条件;常见条件构成分类:
- 比较运算符条件 -->
字段 比较运算符 值,例如:id = 1 (=, !=, >=, <=, >, <) - 逻辑运算符条件 -->
条件1 逻辑关系 条件2,例如:name = "张三" and id = 2 (and, or, not) - 模糊查询:%表示 匹配任意长的值,_ 表示匹配单个长度的值 (这两个条件不能一起用)SQL
-- 不指定长度
字段 like '模糊值' -- 例如:name like "张%"
-- 指定长度 字段 like '模糊值' -- 例如:name like "张_" ```- 范围查询:SQL
非连续: 字段 in (值1, 值2, ...) 例如:city in ("北京", "上海") 连续:字段 between 值1 and 值2 例如:age between 18 and 25 - 空判断:字段 is null
- 非空判断:字段 is not null 或 not 字段 is null (条件前加 not 表示条件取反)
- 比较运算符条件 -->
2)排序
- 应用场景:按照大小规则进行查询所需要的数据。例如:年龄从小到大排序显示人员信息。常用于页面级数据的高低大小的确认
- 语法格式:
select * from 表名 order by 字段名 asc/desc;--> 升序asc / 降序desc (默认升序)
SQL
-- eg:查询所有学生信息,按年龄从大到小排序,年龄相同时,按学号从小到大排序
select * from students order by age desc, studentNo;3)🌟聚合函数
- 应用场景:对列表数据的统计计算方法。例如:统计这个 班级的平均年龄
- 语法:
select 聚合函数 from 表名--> select后的聚合函数可以用多个,多个之间用英文逗号分割- 例如:
select name ,max(age) from students只会返回一条最大age的数据,其他返回的普通列可能是随机拼接的(若分组,则每个分组只会返回一个max) - 使用了聚合函数后,每组只会返回一条记录
- 例如:
- 聚合函数常见分类(聚合函数不能嵌套使用)
- count():统计表中所有的记录数,通过count(*)表示 (count内的参数可以是某个字段,也可以是所有记录 --> *)
- count(*):统计所有记录数,包含某列为空值的记录数,包含空记录
- count(字段):统计某列非空的所有记录数
- max():计算某列的最大值,通过max(字段)表示
- min():计算某列的最小值,通过min(字段)表示
- sum():计算某列的和,通过sum(字段)表示
- avg():计算某列的平均值,通过avg(字段)表示
- count():统计表中所有的记录数,通过count(*)表示 (count内的参数可以是某个字段,也可以是所有记录 --> *)
4)分组查询(有难度)
- 应用场景:表中数据量过大时,可以先将数据分组,然后再查询提高查询效率(一般需求中出现“每种、每个、各个”这类词汇时可以考虑)
- 语法:
- 普通分组查询:
select 字段1, 字段2, 聚合.. from 表名 group by 字段1, 字段2, ...; - 带条件分组查询:
select 字段1, 字段2, 聚合.. from 表名 group by 字段1, 字段2, ... having 条件;- where与having的区别:
- where是对原始数据进行筛选,所以where后不能带聚合函数的条件,但having可以(having带聚合函数条件必须先分组,聚合函数会计算分组后的结果)
- having是对分组之后的结果进行筛选,因而不能单独使用,必须和分组结合使用
- having后面如果跟普通字段构成的条件,必须是分组之后的字段
- where与having的区别:
- 普通分组查询:
SQL
-- 查询各种性别的人数
select sex, count(*) from students group by sex; -- 按照性别分组,并统计每个组的所有记录条数
-- 查询每个班级中各个性别的人数
select class,sex,count(*) from students group by class, sex; -- 先按班级分组,同一个班级再按性别分组,记录每个组的人数(以最小的组为一组)
-- 查询每个平均年龄大于22的班级有哪些
select class from students group by class having avg(age) > 22;
-- 查询每个班级中女生的平均年龄大于22岁的班级有哪些
-- 在数据量大的情况下推荐先进行分组再使用having筛选(分组前先where筛选效率太低,分组后筛选效率高)
select class from students group by class, sex having avg(age) > 22 and sex = '女'; -- avg函数会计算每个分组的平均年龄(先按班级分组,再按性别分组,计算出分组的平均年龄后,再筛选出性别女生即可)
select class from students where sex='女' group by class having avg(age) > 22; -- 另一种解法
-- 该SQL语句会先筛选出性别为女的所有记录,然后再按class分组,再取出剩余记录的分组进行avg计算,最后再根据select class 取出指定字段的记录5)分页查询
- 应用场景:取最大/最小值记录数据时使用,通常结合排序,排序后针对当前页面,从start位置开始,返回 count 条数据
- 常见应用:分页常常和排序结合使用,对应最大最小值条件的应用
- 语法:
select * from 表名 limit start, count- start:下标/索引,表示从第几条开始(数据位置),默认从0开始计数,下标0代表的是第1条记录
- count:需要显示的记录数
select * from 表名 limit 2:只取前两行(开始位置下标默认为0)
SQL
select * from students limit 0, 3
select * from students limit 3 -- 这两行语句作用一致6)连接查询(有难度,代码量大)(关联查询之一)
1. 当内连接/外连接出现多个内连接/外连接同时使用时(多个内连接,多个外连接这两种情况),每次连接都是基于上一次操作得到的“临时表”作为左表(或参与连接的表),再与下一个表进行连接。
2. 一般多个外连接都是使用同一种外连接,例如:第一次使用left join,后续就都使用left join,避免复杂化问题
3. 内/外连接从左到右,都基于原表关联
例如:
SELECT *
FROM students s -- 都使用原表进行关联
LEFT JOIN scores sc ON s.id = sc.student_id
LEFT JOIN awards aw ON s.id = aw.student_id;- 应用场景:将相关联的多张表进行连接,并查询所需要的数据
- 本质:两张表中有公共列(不一定是主键和外键,但匹配列的值一定要相等)
- 分类:
- 内连接:左右两张表都能匹配到的公共列
- 取两张表的公共列对应的记录,根据公共列(有数据的公共列)将两表的其他列拼接起来,形成一张新表,记录数与两者公共列的最小值等同
- 语法:
select * from 表1 inner join 表2 on 表1.列=表2.列
- 外连接:需求中出现一张表需要显示全部数据时考虑使用
- 能用左连接就一定能用右连接
- 左连接:左右两边的公共数据+左表特有的数据(即:左表显示全部数据),右表只显示与公共列匹配的数据,不存在的数据用null表示
- 不存在的数据-->左表有但右表没有的数据
- 语法:
select * from 表1 left join 表2 on 表1.列=表2.列
- 右连接:左右两边的公共数据+右表特有的数据(即:右表显示全部数据),左表只显示与公共列匹配的数据,不存在的数据用null表示
- 语法:
select * from 表1 right join 表2 on 表1.列=表2.列
- 语法:
- 图例:
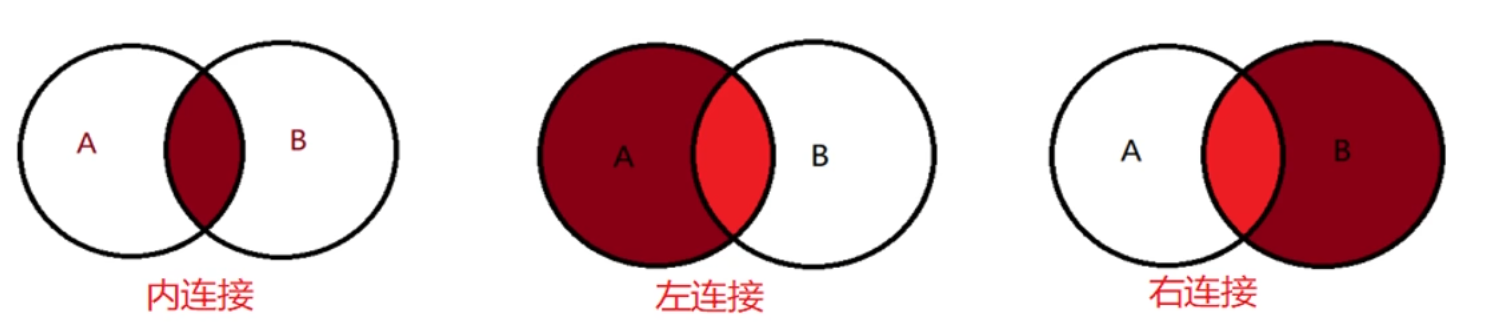
- 内连接:左右两张表都能匹配到的公共列
SQL
-- 内连接
-- 查询学生信息及成绩(信息和成绩存储在两张不同的表中,但这两张表都有一个公共列:studentNo)。
-- 内连接选择的是两张表的公共数据,记录数取两表最小
-- 该SQL的意思是,将students表和scores表进行内连接,公共列是studentNo
select * from students inner join scores on students.studentNo = scores.studentNo;
select * from students st inner join scores sc on st.studentNo = sc.studentNo; -- 起别名
-- 多张表的关联
-- 查询学生信息及学生的课程对应的成绩
select st.*, co.name, sc.score from student st
inner join scores sc on st.studentNo = sc.studentNo
inner join courses co on sc.courseNo = co.courseNo;SQL
-- 右连接(显示右表全部信息,左表没有的用null填充)
-- 查询所有学生的成绩,包括没有成绩的学生 --> 需要成绩信息和学生信息(包括有成绩和无成绩的学生信息)
-- 学生信息需要显示全部
select * from scores sc
right join students st on sc.studentNo = st.studentNo
-- 一般认为第一张表是左表,另一张是右表SQL
-- 左连接
select * from students st
left join scores sc on sc.studentNo = st.studentNo7)子查询(理解有难度,使用不难)(关联查询之二)
- 应用场景:涉及多表关联,想办法在一张表中查到结果【过滤条件或临时表需要另一个SQL查询的场景】
- 子查询构成:
- 主查询:括号外面的select查询
- 子查询:括号里面的select查询
- 子查询具体应用 :
- 作为条件:子查询结果如果是一行一列/多行一列/一行多列,可以直接作为查询条件(where后的条件)
- 作为数据源(临时表):子查询结果是多行多列(临时表),需要结合连接查询
SQL
-- 情况1:作为条件
-- 查询大于平均年龄的学生信息
select * from students where age > (
select avg(age) from students
);
-- 查询与李明同班级同年龄的学生信息
select * from students where (class, age) =(
select class, age from students where name='李明'
);
-- 查询18岁学生的成绩(子查询返回结果大于 1 条记录)
select score from scores where studentNo in (
select studentNo from students where age=18
);SQL
-- 情况2:作为数据源(临时表)
-- 查询数据库和系统测试这两门课程的成绩
select tmp.name, sc.score from scores sc
inner join (select * from courses where name in ('数据库', '系统测试')) tmp -- 给临时表起别名为tmp
on sc.courseNo = tmp.courseNo;SQL语句的书写顺序
- 总顺序:
select ... from 表名 inner join 表名 on ... where 条件 group by ... having ... order by ... limit ...
贡献者
 freeway348
freeway348