Agent-鸿蒙小车环境配置及基础介绍
1.整体介绍
1.1 系统架构
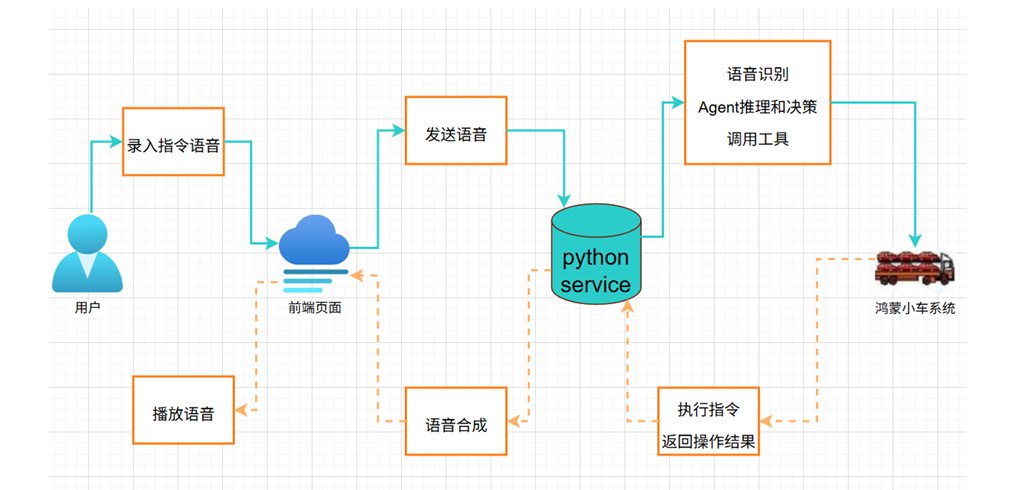
1.2 系统流程
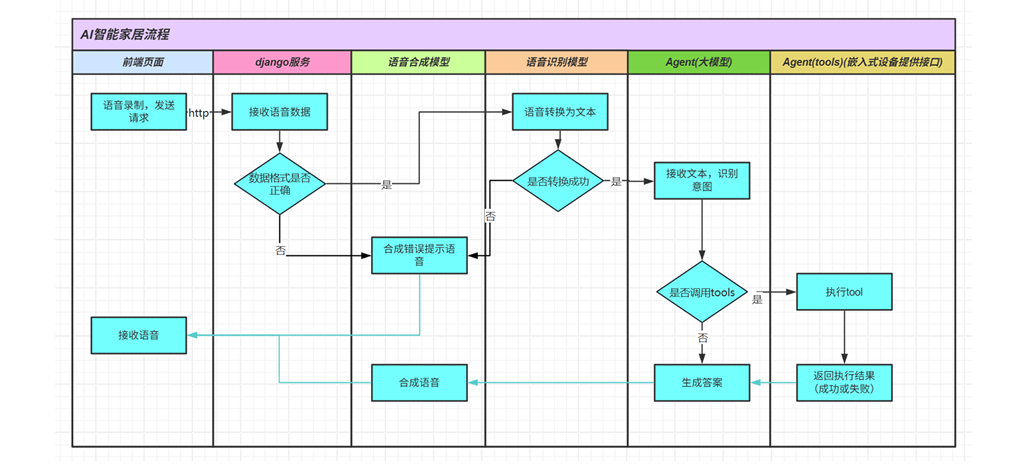
1.3 AI技术栈
环境:
Anaconda:2024
IDE:
Pycharm:2024
HBuilderX:latest
技术栈:
后台服务:
Python:3.11
Django:latest
LangChain/LangGraph:1.2.0
前端页面:
html、css、javascript
1.4 安装
Anaconda:详见安装包说明
Pycharm:详见安装包说明
1.5 虚拟环境
创建虚拟环境:
打开anaconda prompt命令提示符对话框,输入:
conda create -n dly_env python=3.11说明:dly_env是虚拟环境名称
激活虚拟环境:
输入:
conda activate dly_env1.6 安装基础依赖包
需要安装的基础依赖包如下:
pip install django-cors-headers # 是django与前端连接的重要依赖,主要解决跨域访问问题,使得前端与django后端运行在不同域名/端口时仍然能连通,是用于在HTTP响应头中添加CORS相关的配置
pip install requests
pip install "langchain[openai]"
# 相当于下边的命令:
# pip install langchain langchain-openai
pip install dotenv # 让开发者可以把配置文件放在.env文件中,代码运行时可以自动读取.env环境配置,.env文件不要提交到git,实现项目隔离,便于分享1.7 创建django项目
使用Anaconda Prompt命令形式创建django项目
conda activate dly_env # 激活之前创建的虚拟环境
D:
cd D:\AI # 切换目录
django-admin startproject dly_server
# 创建django项目的命令: django-admin startproject [项目名称(不能有横杠)]1.8 基本架构解释
这些都是创建项目后自动生成的代码段
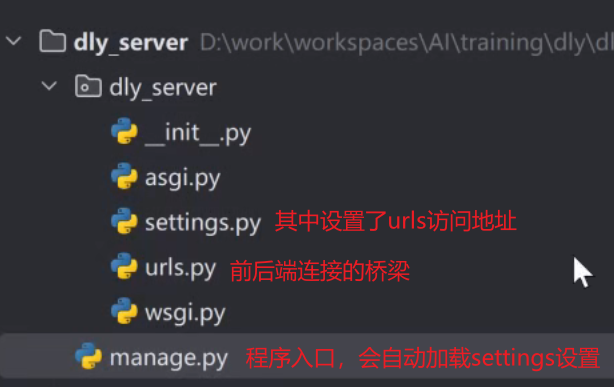
1)manage.py
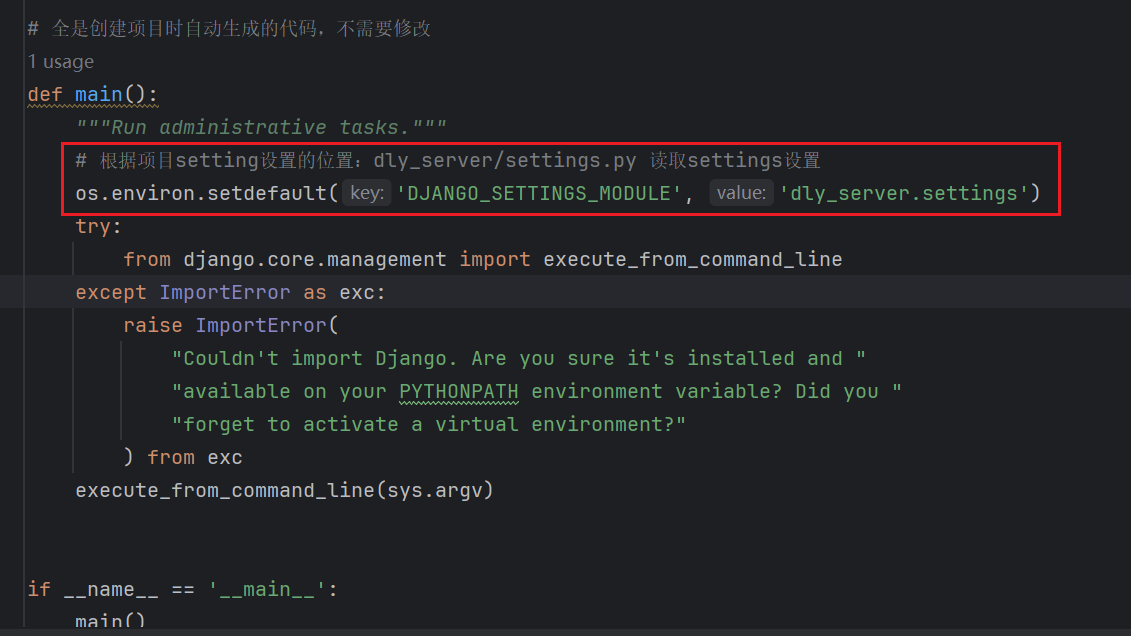
2)settings.py

3)urls.py
程序启动后,会自动读取settings设置,并将settings中的urls配置读取,自动建立URL路径到函数,如前端调用api接口(完整url),django会自动与urls.py中找到对应函数并执行,随后返回JSON响应给前端 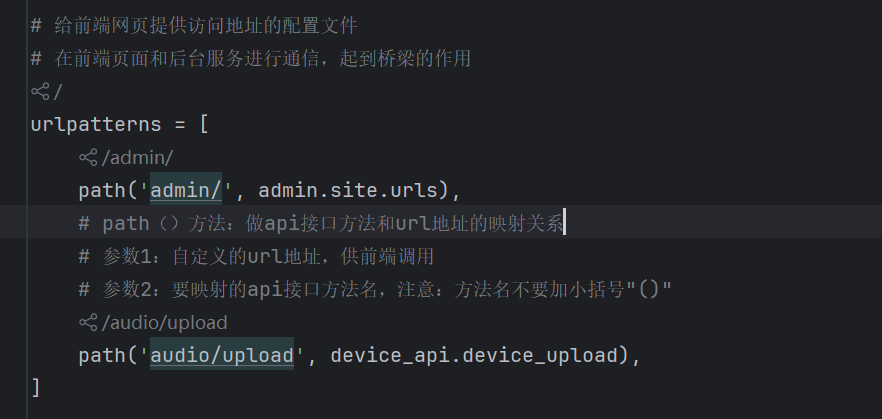 例如:audio/upload就是api接口,组成的完整url就是:http://localhost:8000/audio/upload,而device_api.device_upload就是调用该接口后自动执行的函数
例如:audio/upload就是api接口,组成的完整url就是:http://localhost:8000/audio/upload,而device_api.device_upload就是调用该接口后自动执行的函数
1.9 查看Django域名
启动Django后台服务:  如果是社区版Pycharm,也可以通过命令行方式运行(在Terminal里):
如果是社区版Pycharm,也可以通过命令行方式运行(在Terminal里):  当然也可以在Anaconda prompt里启动,需要先用cd命令切换到目标文件夹位置 随后可以在运行后台Run窗口看到Django服务器的域名,用于前端调用Django的API接口时使用
当然也可以在Anaconda prompt里启动,需要先用cd命令切换到目标文件夹位置 随后可以在运行后台Run窗口看到Django服务器的域名,用于前端调用Django的API接口时使用 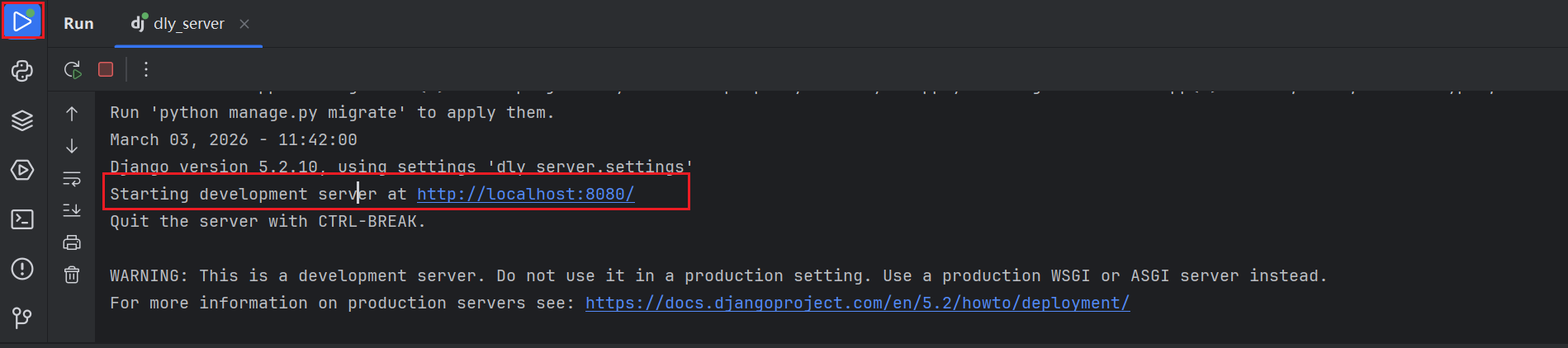
2.智能体核心概念:它是什么?
Agent 的核心思想是使用一个大语言模型(LLM)作为其“大脑”或“决策核心”,来理解用户需求、制定计划、选择工具(Tools)、执行动作(Actions)、并观察结果,最终完成一个复杂的任务。
简单来说,一个 Agent 的运作模式是: 思考(Think) -> 行动(Act) -> 观察(Observe) -> ... -> 最终完成
这非常类似于人类的思考方式。比如,当被问到“奥利奥卡路里高吗?”时,一个 Agent 可能会这样工作:
- 思考:“用户问的是奥利奥的卡路里。我自己没有实时数据,但我可以调用网络搜索工具。”
- 行动:调用
google_search工具,输入查询关键词 “Oreo calorie content”。 - 观察:工具返回了搜索结果,例如 “一份(3块)奥利奥含有约 160 卡路里”。
- 再思考:“我得到了数据。现在需要判断这个数值是否算‘高’。我可以调用一个计算工具,将其与常见零食对比,或者直接用我的知识进行推理。”
- 再行动/回答:基于推理,生成最终答案:“一份(3块)奥利奥大约含有160卡路里。相比于一些水果(如一个苹果约95卡),这个热量相对较高,属于能量密度较高的零食,应适量食用。”
2.1 为什么需要 Agents?解决了什么问题?
尽管LLM本身非常强大,但它有固有的局限性:
- 知识滞后与幻觉:如前所述,LLM的知识有截止日期,且会编造信息。
- 无法执行外部动作:LLM可以写代码,但不能真正运行代码;它可以描述如何发送邮件,但不能真的帮你发邮件。
- 数学计算、实时信息获取等能力弱:LLM可能不擅长精确计算或获取最新信息。
Agents 通过“工具使用(Tool Use)”能力,将 LLM 的推理和语言能力与外部工具的强大功能结合起来,突破了LLM自身的限制,使其成为一个真正的“数字助手”。
3.核心组成部分
一个典型的 Agent 由以下几个关键部分构成:
LLM (大脑)
负责所有的推理和决策。它决定下一步该做什么,使用哪个工具,以及如何解释工具返回的结果。主要功能包括:
- 理解用户意图和任务需求
- 进行逻辑推理和规划
- 决定是否需要调用工具
- 生成工具调用的正确参数
工具 (Tools)
Agent 可以调用的外部函数。这是 Agent 能力的扩展。包括:
- 搜索工具、计算器、API调用等预置工具
- 自定义工具:可封装任意业务逻辑(如数据库操作、文件处理)
- 关键特性:每个工具需明确定义功能描述和参数规范,便于LLM准确调用
记忆(Memory):
- Memory为Agent提供上下文感知能力,使其能够记住之前的交互历史并基于上下文做出决策。
- LangChain中的记忆系统分为短期记忆(维护当前对话的上下文) 和长期记忆(支持跨对话会话的知识持久化)。
- 在LangChain1.0中,记忆系统与LangGraph的状态管理深度融合,支持更复杂和结构化的状态保持
代理执行器 (Agent Executor)
- 在LangChain 1.0的架构中,AgentExecutor继续扮演执行协调器的关键角色,负责选代运行代理直至满足停止条件。
- 新版本中,AgentExecutor获得了更强大的流程控制能力,包括循环控制(通过max_iterations参数防止无限循环)、异常处理(可配置的解析错误处理)和可观测性。
- 用于激活我们创建好的智能体
4.工作原理
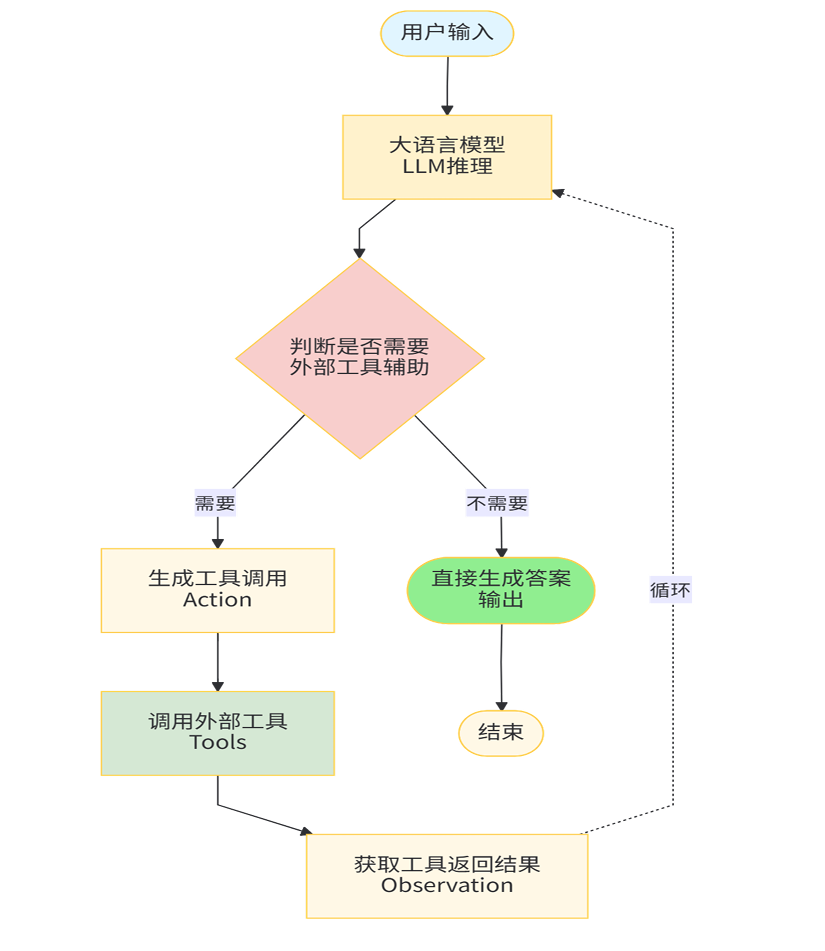
Agent 工作原理:
- 输入解析:Agent首先接收用户输入,解析其意图和关键参数。输入解析器负责标准化用户请求,提取可供工具使用的结构化参数。
- LLM推理:解析后的输入与当前状态(包括记忆和历史记录)一起传递给LLM进行推理。LLM基于预设的提示词模板分析情况,决定下一步行动——直接回答还是调用工具。
- 工具调用:如果LLM决定调用工具,AgentExecutor会执行相应的工具函数,并获取执行结果。工具调用可能涉及外部API访问、数据库查询或计算操作等。
- 观察与迭代:工具返回的结果作为"观察"被反馈给Agent,这些信息与之前的状态一起形成新的上下文,传递给LLM进行下一轮推理。这个循环持续进行,直到LLM认为已获得足够信息来生成最终答案。
- 结果整合:当循环结束时,Agent整合所有获取的信息,生成格式化的最终答案返回给用户。同时,重要的交互信息可能被存储在记忆系统中,供未来会话使用。
贡献者
 freeway348
freeway348