关联规则挖掘
字数
1108 字
阅读时间
5 分钟
一、简介
- 若两个或多个数据项的取值之间重复出现并且概率很高时,它就存在某种关联,可以建立起这些数据项的关联规则
- 关联规则反映一个事物和其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物发生就能够预测与它相关联的其他事物的发生
应用领域
- 超市购物篮分析
- Web挖掘
- 生物信息网络
- 社交网络分析
- ...
经典范例
- 购物篮(Market Basket)分析。通过发现顾客放入购物篮中商品之间的同线关系来分析顾客的购买习惯,从而实现商品的交叉销售和推荐
二、定义
定义1
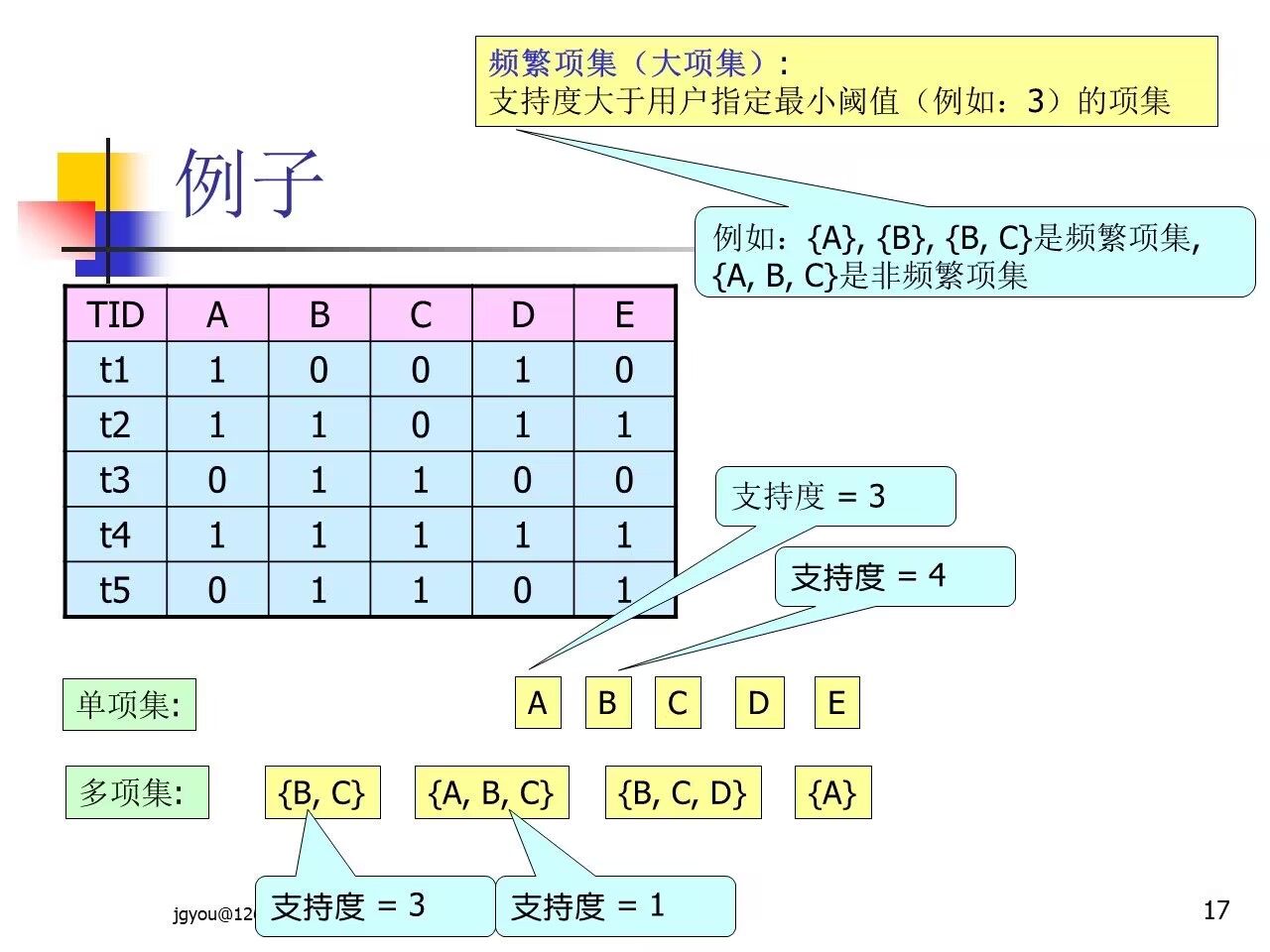
- 项的集合称为项集(Itemset),包含
k个项的项集称之为k-项集
定义2
- 关联规则是形如
的蕴含式,这里 , ,并且
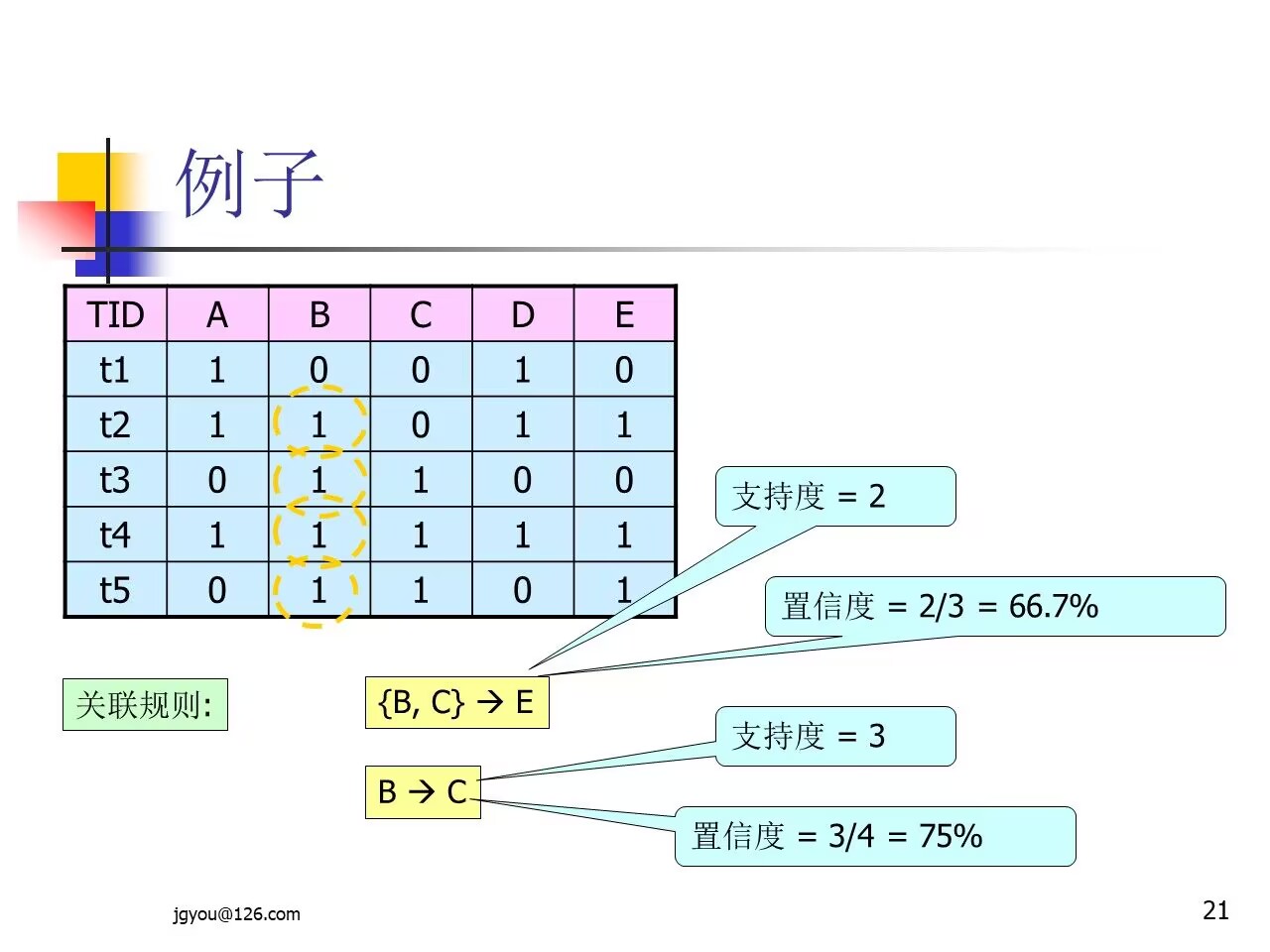
定义3:规则的支持度
- 规则
在 数据库D中具有支持度S,表示S是D中事务同时包含AB的百分比,它是概率P(AB),即:- 其中
|D|表示事务数据库D的事务总个数,表示A、B两个项集同时发生的事务个数 - 即:
前置项A和后置项B的并集所出现的次数在总事务记录数D中的占比
- 其中
定义4:规则的置信度
- 规则
也有置信度 C,表示C是包含项集A的同时也包含项集B,相对于包含A项集的百分比,这是条件概率P(B|A),即:前置项A和前置项B的并集所出现的次数在前置项A所出现次数中的占比- 其中
|A|表示数据库中包含项集A的事务个数
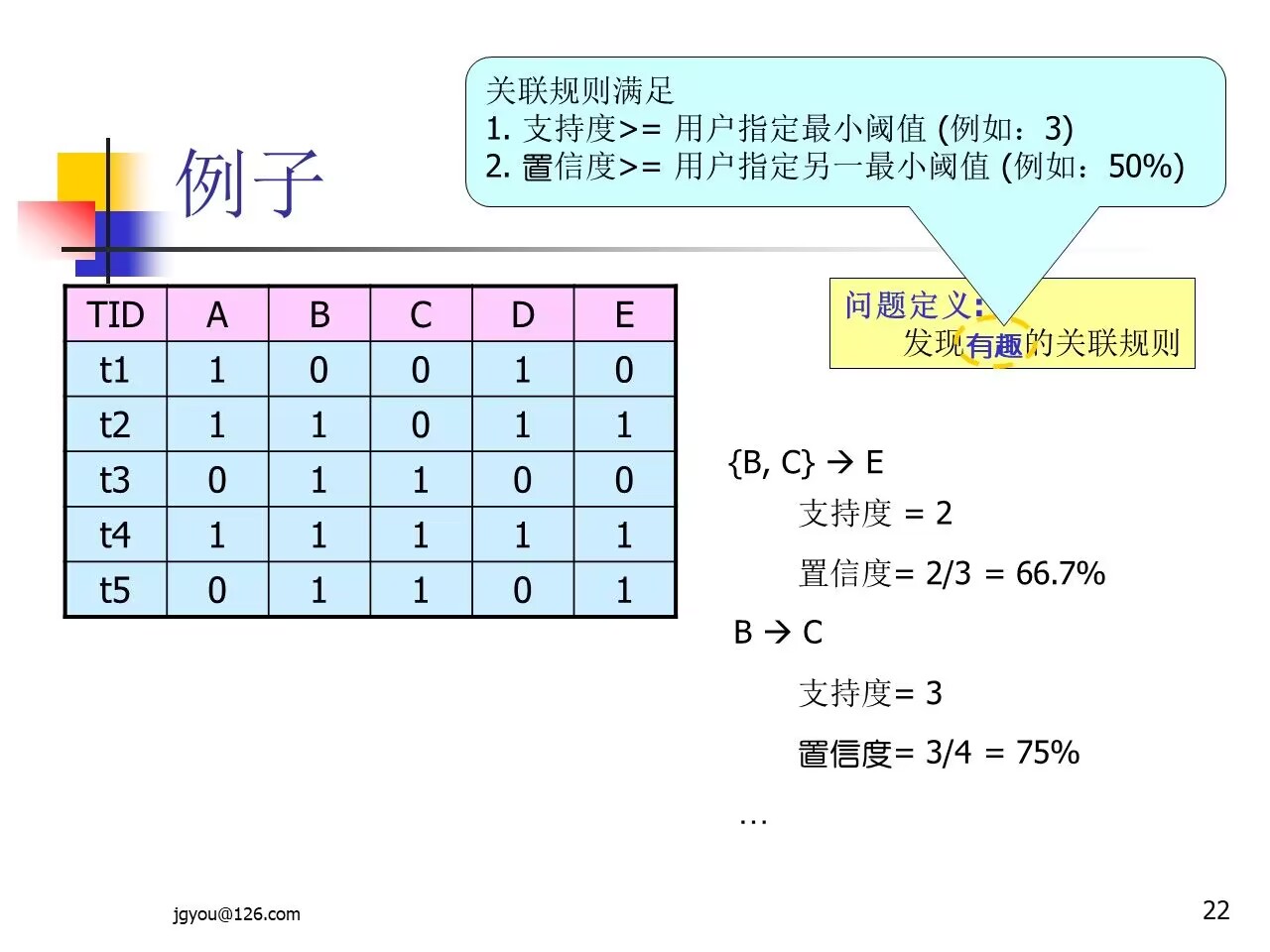
定义5:阈值
- 在事务数据库中找出有用的关联规则,需要由用户确定两个阈值:最小支持度(min_sup)和最小置信度(min_conf)
定义6
- 如果项集满足最小支持度(
),则它称之为频繁项集(Frequent Itemset)
定义7:强关联规则
- 同时满足最小支持度(min_sup)和最小置信度(min_conf)的规则称之为强关联规则,即:
- 成立时,规则称之为强关联规则
例子说明:

- 纠错:支持度大于等于支持度最小阈值(min_sup)的才是频繁项集


三、Apriori算法
地位:十大经典数据挖掘算法之一特点:先验性质
- 频繁项集的子集一定是频繁项集
- 非频繁项集的超集一定是非频繁项集
- 超集:以该集合为子集的集合
- 如:现有
集合{A,B},其子集为:{A},{B},超集为:{A,B,C,...}
- 如:现有
- 超集:以该集合为子集的集合
应用例子:

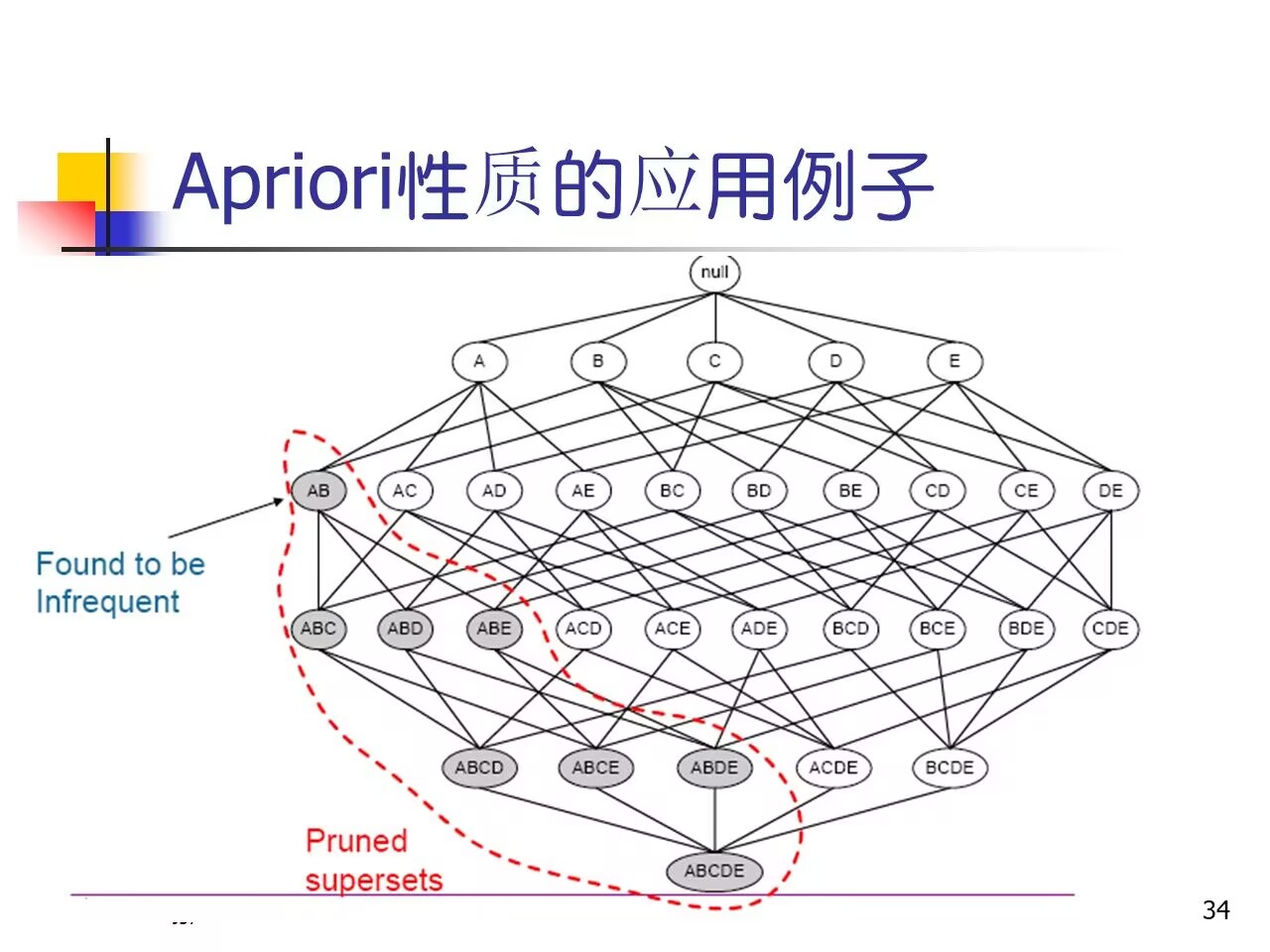
- 找
频繁K+1项集:将频繁K-项集两两连接(有相同项才能连接)后再剪枝
算法过程:更优算法
- Apriori使用一种称作逐层搜索的迭代方法,
K-项集用于探索K+1-项集
- 首先,找出
频繁1-项集的集合。该集合记作。 用于找 频繁2-项集的集合,而 用于找 - 如此下去,直到不能找到
K-项集。找每个都需要一次数据库扫描
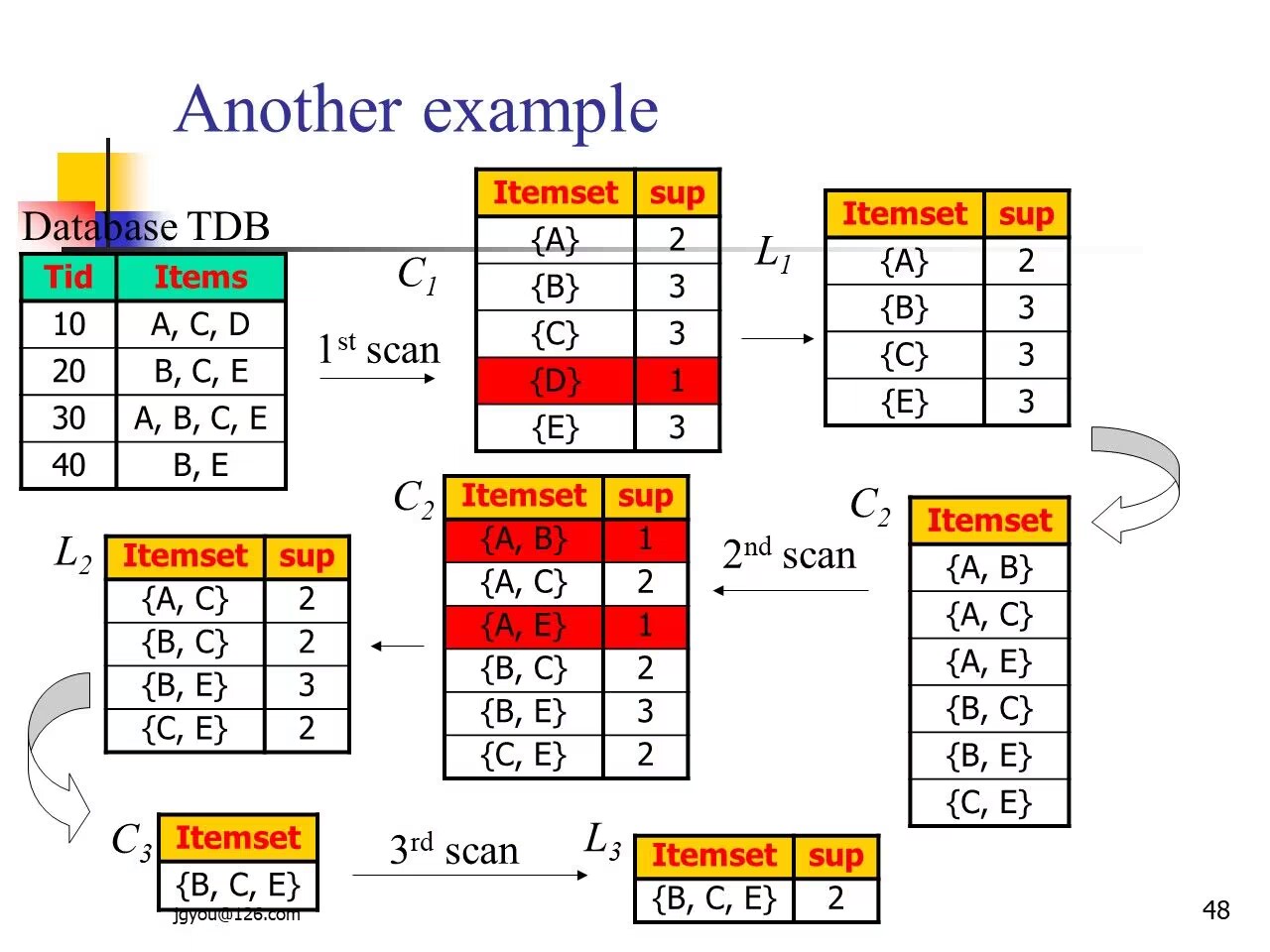
具体实践:
- 查找过程:


- 如:
过程中,先用 2项集{A,C}和{B,C}进行连接,连接结果为:{A,B,C},其支持度(sup)为1,小于最小支持度(min_sup),所以将该剪枝,其他步骤以此类推
- 如:

贡献者
 freeway348
freeway348